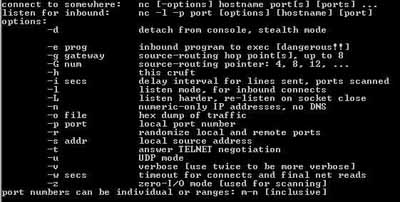
Programmation shell
L e shell n’est pas qu’un simple interpréteur de commandes, mais dispose d’un véritable langage de programmation avec notamment une gestion des variables, des tests et des boucles, des opérations sur variables, des fonctions…
 Structure et execution d’un script
Structure et execution d’un script
Toutes les instructions et commandes sont regroupées au sein d’un script. Lors de son exécution, chaque ligne sera lue une à une et exécutée. Une ligne peut se composer de commandes internes ou externes, de commentaires ou être vide. Plusieurs instructions par lignes sont possibles, séparées par le « ; » ou liées conditionnellement par « && » ou « || ». Le « ; » est l’équivalent d’un saut de ligne.
Par convention les shell scripts se terminent généralement (pas obligatoirement) par « .sh » pour le Bourne Shell et le Bourne Again Shell, par « .ksh » pour le Korn Shell et par « .csh » pour le C Shell.
Pour rendre un script exécutable directement :
$ chmod u+x monscript
Pour l’exécuter :
$ ./monscript
Pour éviter le ./ :
$ PATH=$PATH:.
$ monscript
Quand un script est lancé, un nouveau shell « fils » est créé qui va exécuter chacune des commandes. Si c’est une commande interne, elle est directement exécutée par le nouveau shell. Si c’est une commande externe, dans le cas d’un binaire un nouveau fils sera créé pour l’exécuter, dans le cas d’un shell script un nouveau shell fils est lancé pour lire ce nouveau shell ligne à ligne.
Une ligne de commentaire commence toujours par le caractère « # ». Un commentaire peut être placé en fin d’une ligne comportant déjà des commandes.
# La ligne suivante effectue un ls
ls # La ligne en question
La première ligne a une importance particulière car elle permet de préciser quel shell va exécuter le script #!/bin/sh
#!/bin/ksh
Dans le premier cas c’est un script Bourne, dans l’autre un script Korn.
Les variables
On en distingue trois types : utilisateur, système et spéciales. Le principe est de pouvoir affecter un contenu à un nom de variable, généralement un chaîne de caractère, ou des valeurs numériques.
Nomenclature
Un nom de variable obéit à certaines règles :
1. Il peut être composé de lettres minuscules, majuscules, de chiffres, de caractères de soulignement
2. Le premier caractère ne peut pas être un chiffre
3. Le taille d’un nom est en principe illimité (il ne faut pas abuser non plus)
4. Les conventions veulent que les variables utilisateur soient en minuscules pour les différencier des variables système. Au choix de l’utilisateur.
Declaration et affectation
Une variable est déclarée dès qu’une valeur lui est affectée. L’affectation est effectuée avec le signe « = », sans espace avant ou après le signe. var=Bonjour
On peut aussi créer des variables vides. Celle-ci existera mais sans contenu. var=
Acces et affichage
On accède au contenu d’une variable en plaçant le signe « $ » devant le nom de la variable. Quand le shell rencontre le « $ », il tente d’interpréter le mot suivant comme étant une variable. Si elle existe, alors le $nom_variable est remplacé par son contenu, ou par un texte vide dans le cas contraire.
On parle aussi de référencement de variable.
$ chemin=/tmp/seb
$ pwd
/home/toto
$ ls $chemin
dump.log fic4 lien_fic1 liste_ls rep1 seb2
fic1 hardlink2_fic2 lien_fic2 ls.txt rep2 toto.tar.gz
fic2 hardlink3_fic2 liste mypass resultat.txt users
fic3 hardlink_fic2 liste2 nohup.out seb1
$ cd $chemin
$ pwd
/tmp/seb
$ cd $chemin/rep1
$ pwd
/tmp/seb/rep1
Pour afficher la liste des variables on utilise la commande set. Elle affiche les variables utilisateur et les variables système, nom et contenu. La commande echo permet d’afficher le contenu de variables spécifiques.
$ a=Jules
$ b=Cesar
$ set
EDITMODE=emacs
HOME=/home/seb
LD_LIBRARY_PATH=/mor/app/oracle/product/8.1.7/lib
LOGNAME=seb
MAIL=/usr/spool/mail/seb
MAILCHECK=600
MANPATH=/usr/man:/sqlbt/datatools/obacktrack/man
PATH=/home/oracle/bin:/usr/bin:.:/mor/app/oracle/product/8.1.7/bin:/sqlbt/datatools/obacktrack/bin:
PS1=$
PS2=>
SHELL=/bin/csh
SHLVL=1
TERM=xterm
USER=seb
a=Jules
b=Cesar
$ echo $a $b a conquis la Gaule
Jules Cesar a conquis la Gaule
Une variable peut contenir des caractères spéciaux, le principal étant l’espace. Mais $ c=Salut les copains
les: not found
$ echo $c
Ne marche pas.
Pou r cela il faut soit verrouiller les caractères spéciaux un par un, soit de les mettre entre guillemets ou apostrophes.
c=Salut\ les\ Copains # Solution lourde
c=”Salut les copains” # Solution correcte
c=’Salut les copains’ # Solution correcte
La principale différence entre les guillemets et les apostrophes est l’interprétation des variables et des substitutions. ” et ‘ se vérouillent mutuellement.
$ a=Jules
$ b=Cesar
$ c=”$a $b a conquis la Gaule”
$ d=’$a $b a conquis la Gaule’
$ echo $c
Jules Cesar a conquis la Gaule
$ echo $d
$a $b a conquis la Gaule
$ echo “Unix c’est top”
Unix c’est top
$ echo ‘Unix “trop bien”‘
Unix “trop bien”
Supression et protection
On supprime une variable avec la commande unset. On peut protéger une variable en écriture et contre sa suppression avec la commande readonly. Une variable en lecture seule même vide est figée. Il n’existe aucun moyen de la replacer en écriture et de la supprimer, sauf à quitter le shell.
$ a=Jules
$ b=Cesar
$ echo $a $b
Jules Cesar
$ unset b
$ echo $a $b
Jules
$ readonly a
$ a=Neron
a: is read only
$ unset a
a: is read only
Exportation
Par défaut une variable n’est accessible que depuis le shell où elle a été définie. $ a=Jules
$ echo ‘echo “a=$a”‘ > voir_a.sh
$ chmod u+x voir_a.sh
$ ./voir_a.sh
a=
La commande export permet d’exporter une variable de manière à ce que son contenu soit visible par les scripts et autres sous-shells. Les variables exportées peuvent être modifiées dans le script, mais ces modifications ne s’appliquent qu’au script ou au sous-shell. $ export a ./voir_a.sh a=Jules $ echo ‘a=Neron ; echo “a=$a”‘ >> voir_a.sh $ ./voir_a.sh a=Jules a=Neron $ echo $a Jules
Accolades
Les accolades de base « {} » permettent d’identifier le nom d’une variable. Imaginons la variable fichier contenant le nom de fichier ‘liste’. On veut copier liste1 en liste2.
$ fichier=liste
$ cp $fichier2 $fichier1
usage: cp [-fhip] [–] source_file destination_file
or: cp [-fhip] [–] source_file … destination_directory
or: cp [-fhip] [-R | -r] [–]
[source_file | source_directory] … destination_directory
Ça ne fonctionne pas car ce n’est pas $fichier qui est interprété mais $fichier1 et $fichier2 qui n’existent pas.
$ cp ${fichier}2 ${fichier}1
Dans ce cas, cette ligne équivaut à
$ cp liste2 liste1
Les accolades indiquent que fichier est un nom de variable.
Accolades et remplacement conditionnel
Les accolades disposent d’une syntaxe particulière. {variable:Remplacement}
Selon la valeur ou la présence de la variable, il est possible de remplacer sa valeur par une autre.
| Remplacement |
Signification |
| {x:-texte} |
si la variable x est vide ou inexistante, le texte prendra sa place. Sinon c’est le contenu de la variable qui prévaudra. |
| {x:=texte} |
si la variable x est vide ou inexistante, le texte prendra sa place et deviendra la valeur de la variable. |
| {x:+texte} |
si la variable x est définie et non vide, le texte prendra sa place. Dans le cas contraire une chaîne vide prend sa place. |
| {x:?texte} |
si la variable x est vide ou inexistante, le script est interrompu et le message texte s’affiche. Si texte est absent un message d’erreur standard est affiché. |
$ echo $nom
$ echo ${nom:-Jean}
$ echo $nom
$ echo ${nom:=Jean}
Jean
$ echo $nom
Jean
$ echo ${nom:+”Valeur définie”}
Valeur définie
$ unset nom
$ echo ${nom:?Variable absente ou non définie}
nom: Variable absente ou non définie
$ nom=Jean
$ echo ${nom:?Variable absente ou non définie}
Jean
Variables système
En plus des variables que l’utilisateur peux définir lui-même, le shell est lancé avec un certain nombre de variables prédéfinies utiles pour un certain nombre de commandes et accessibles par l’utilisateur.
Le contenu de ces variables système peut être modifié mais il faut alors faire attention car certaines ont une incidence directe sur le comportement du système.
| Variable |
Contenu |
| HOME |
Chemin d’accès du répertoire utilisateur. Répertoire par défaut en cas de cd. |
| PATH |
Liste de répertoires, séparés par des « : » où le shell va rechercher les commandes externes et autres scripts et binaires. La recherche se fait dans l’ordre des répertoires saisis. |
| PS1 |
Prompt String 1, chaîne représentant le prompt standard affiché à l’écran par le shell en attente de saisie de commande. |
| PS2 |
Prompt String 2, chaîne représentant un prompt secondaire au cas où la saisie doit être complétée. |
| IFS |
Internal Field Separator, liste des caractères séparant les mots dans une ligne de commande. Par défaut il s’agit de l’espace de la tabulation et du saut de ligne. |
| MAIL |
chemin et fichier contenant les messages de l’utilisateur |
| MAILCHECK |
intervalle en secondes pour la vérification de présence d’un nouveau courrier. Si 0 alors la vérification est effectuée après chaque commande. |
| SHELL |
Chemin complet du shell en cours d’exécution |
| LANG |
Définition de la langue à utiliser ainsi que du jeu de caractères |
| LC_COLLATE |
Permet de définir l’ordre du tri à utiliser (si LANG est absent) |
| LC_NUMERIC |
Format numérique à utiliser |
| LC_TIME |
Format de date et d’heure à utiliser |
| LC_CTYPE |
Détermination des caractères et signes devant ou ne devant pas être pris en compte dans un tri. |
| USER |
Nom de l’utilisateur en cours. |
| LD_LIBRARY_PATH |
Chemin d’accès aux bibliothèques statiques ou partagées du système. |
| MANPATH |
Chemin d’accès aux pages du manuel. |
| LOGNAME |
Nom du login utilisé lors de la connexion. |
Variables speciales
Il s’agit de variables accessibles uniquement en lecture et dont le contenu est généralement contextuel.
| Variable |
Contenu |
| $? |
Code retour de la dernière commande exécutée |
| $$ |
PID du shell actif |
| $! |
PID du dernier processus lancé en arrière-plan |
| $- |
Les options du shell |
$ cat param.sh
#!/usr/bin/sh
echo “Nom : $0”
echo “Nombre de parametres : $#”
echo “Parametres : 1=$1 2=$2 3=$3”
echo “Liste : $*”
echo “Elements : $@”
$ param.sh riri fifi loulou
Nom : ./param.sh
Nombre de parametres : 3
Parametres : 1=riri 2=fifi 3=loulou
Liste : riri fifi loulou
Elements : riri fifi loulou
La différence entre $@ et $* ne saute pas aux yeux. Reprenons l’exemple précédent avec une petite modification :
$ param.sh riri “fifi loulou”
Nom : ./param.sh
Nombre de parametres : 2
Parametres : 1=riri 2=fifi loulou 3=
Liste : riri fifi loulou
Elements : riri fifi loulou
Cette fois-ci il n’y a que deux paramètres de passés. Pourtant les listes semblent visuellement identiques. En fait si la première contient bien “riri fifi loulou”
La deuxième contient
“riri” “fifi loulou”
Soit bien deux éléments. Dans les premier exemple nous avions “riri” “fifi” “loulou”
Parametres de position
Les paramètres de position sont aussi des variables spéciales utilisées lors d’un passage de paramètres à un script.
Description
| Variable |
Contenu |
| $0 |
Nom de la commande (du script) |
| $1-9 |
$1,$2,$3… Les neuf premiers paramètres passés au script |
| $# |
Nombre total de paramètres passés au script |
| $* |
Liste de tous les paramètres au format “$1 $2 $3 …” |
| $@ |
Liste des paramètres sous forme d’éléments distincts “$1” “$2” “$3” … |
Redéfinition des paramètres
Outre le fait de lister les variables, la commande set permet de redéfinir le contenu des variables de position. Avec set valeur1 valeur2 valeur3 …
$1 prendra comme contenu valeur1, $2 valeur2 et ainsi de suite.
$ cat param2.sh
#!/usr/bin/sh
echo “Avant :”
echo “Nombre de parametres : $#”
echo “Parametres : 1=$1 2=$2 3=$3 4=$4”
echo “Liste : $*”
set alfred oscar romeo zoulou
echo “apres set alfred oscar romeo zoulou”
echo “Nombre de parametres : $#”
echo “Parametres : 1=$1 2=$2 3=$3 4=$4”
echo “Liste : $*”
./param2.sh riri fifi loulou donald picsou
Avant :
Nombre de parametres : 5
Parametres : 1=riri 2=fifi 3=loulou 4=donald
Liste : riri fifi loulou donald picsou
apres set alfred oscar romeo zoulou
Nombre de parametres : 4
Parametres : 1=alfred 2=oscar 3=romeo 4=zoulou
Liste : alfred oscar romeo zoulou
Réorganisation des paramètres
La commande shift est la dernière commande permettant de modifier la structure des paramètres de position. Un appel simple décale tous les paramètres d’une position en supprimant le premier : $2 devient $1, $3 devient $2 et ainsi de suite. Le $1 originel disparaît. $#, $* et $@ sont redéfinis en conséquence.
La commande shift suivie d’une valeur n effectue un décalage de n éléments. Ainsi avec
shift 4
$5 devient $1, $6 devient $2, …
$ cat param3.sh
#!/usr/bin/sh
set alfred oscar romeo zoulou
echo “set alfred oscar romeo zoulou”
echo “Nombre de parametres : $#”
echo “Parametres : 1=$1 2=$2 3=$3 4=$4”
echo “Liste : $*”
shift
echo “Après un shift”
echo “Nombre de parametres : $#”
echo “Parametres : 1=$1 2=$2 3=$3 4=$4”
echo “Liste : $*”
$ ./param3.sh
set alfred oscar romeo zoulou
Nombre de parametres : 4
Parametres : 1=alfred 2=oscar 3=romeo 4=zoulou
Liste : alfred oscar romeo zoulou
Après un shift
Nombre de parametres : 3
Parametres : 1=oscar 2=romeo 3=zoulou 4=
Liste : oscar romeo zoulou
Sortie de script
L a commande exit permet de mettre fin à un script. Par défaut la valeur retournée est 0 (pas d’erreur) mais n’importe quelle autre valeur de 0 à 255 peut être précisée. On récupère la valeur de sortie par la variable $?. $ exit 1
Environnement du processus
En principe seules les variables exportées sont accessibles par un processus fils. Si on souhaite visualiser l’environnement lié à un fils (dans un script par exemple) on utilise la commande env.
$ env
PATH=/home/oracle/bin:/usr/bin:.:/mor/app/oracle/product/8.1.7/bin
TERM=xterm
LOGNAME=oracle
USER=oracle
SHELL=/bin/csh
HOME=/home/oracle
SHLVL=1
MAIL=/usr/spool/mail/oracle
ORACLE_SID=ORAP
EPC_DISABLED=TRUE
ORACLE_BASE=/mor/app/oracle
ORACLE_HOME=/mor/app/oracle/product/8.1.7
EDITMODE=emacs
ORATAB=/etc/oratab
La commande env permet de redéfinir aussi l’environnement du processus à lancer. Cela peut être utile lorsque le script doit accéder à une variable qui n’est pas présente dans l’environnement du père, ou qu’on ne souhaite pas exporter. La syntaxe est
env var1=valeur var2=valeur … commande
Si la première option est le signe « – » alors c’est tout l’environnement existant qui est supprimé pour être remplacé par les nouvelles variables et valeurs.
$ unset a
$ ./voir_a.sh
a=
$ env a=jojo ./voir_a.sh
a=jojo
$ echo a=$a
a=
Substitution de commande
Le mécanisme de substitution permet de placer le résultat de commandes simples ou complexes dans une variable. On place les commandes à exécuter entre des accents graves « ` ». (Alt Gr + 7).
$ mon_unix=`uname`
$ echo ${mon_unix}
OSF1
$ machine=`uname -a | cut -d” ” -f5`
$ echo $machine
alpha
Attention, seul le canal de sortie standard est affecté à la variable. Le canal d’erreur standard sort toujours vers l’écran.
Tests de conditions
La commande test permet d’effectuer des tests de conditions. Le résultat est récupérable par la variable $? (code retour). Si ce résultat est 0 alors la condition est réalisée.
Tests sur chaîne
* test -z “variable” : zero, retour OK si la variable est vide (ex test -z “$a”)
* test -n “variable” : non zero, retour OK si la variable n’est pas vide (texte quelconque)
* test “variable” = chaîne : OK si les deux chaînes sont identiques
* test “variable” != chaîne : OK si les deux chaînes sont différentes
$ a=
$ test -z “$a” ; echo $?
0
$ test -n “$a” ; echo $?
1
$ a=Jules
$ test “$a” = Jules ; echo $?
0
Tests sur valeurs numériques
Les chaînes à comparer sont converties en valeurs numériques. La syntaxe est
test valeur1 option valeur2
et les options sont les suivantes :
| Option |
Rôle |
| -eq |
Equal : Egal |
| -ne |
Not Equal : Différent |
| -lt |
Less than : inférieur |
| -gt |
Greater than : supérieur |
| -le |
Less ou equal : inférieur ou égal |
| -ge |
Greater or equal : supérieur ou égal |
$ a=10
$ b=20
$ test “$a” -ne “$b” ; echo $?
0
$ test “$a” -ge “$b” ; echo $?
1
$ test “$a” -lt “$b” && echo “$a est inferieur a $b”
10 est inferieur a 20
Tests fichiers
La syntaxe est test option nom_fichier et les options sont les suivantes :
| Option |
Rôle |
| -f |
Fichier normal |
| -d |
Un répertoire |
| -c |
Fichier en mode caractère |
| -b |
Fichier en mode bloc |
| -p |
Tube nommé (named pipe) |
| -r |
Autorisation en lecture |
| -w |
Autorisation en écriture |
| -x |
Autorisation en exécution |
| -s |
Fichier non vide (au moins un caractère) |
| -e |
Le fichier existe |
| -L |
Le fichier est un lien symbolique |
| -u |
Le fichier existe, SUID-Bit positionné |
| -g |
Le fichier existe SGID-Bit positionné |
$ ls -l
-rw-r–r– 1 oracle system 1392 Aug 14 15:55 dump.log
lrwxrwxrwx 1 oracle system 4 Aug 14 15:21 lien_fic1 -> fic1
lrwxrwxrwx 1 oracle system 4 Aug 14 15:21 lien_fic2 -> fic2
-rw-r–r– 1 oracle system 234 Aug 16 12:20 liste1
-rw-r–r– 1 oracle system 234 Aug 13 10:06 liste2
-rwxr–r– 1 oracle system 288 Aug 19 09:05 param.sh
-rwxr–r– 1 oracle system 430 Aug 19 09:09 param2.sh
-rwxr–r– 1 oracle system 292 Aug 19 10:57 param3.sh
drwxr-xr-x 2 oracle system 8192 Aug 19 12:09 rep1
-rw-r–r– 1 oracle system 1496 Aug 14 16:12 resultat.txt
-rw-r–r– 1 oracle system 1715 Aug 16 14:55 toto.txt
-rwxr–r– 1 oracle system 12 Aug 16 12:07 voir_a.sh
$ test -f lien_fic1 ; echo $?
1
$ test -x dump.log ; echo $?
1
$ test -d rep1 ; echo $?
0
Tests combinés par critères ET OU NON
On peut effectuer plusieurs tests avec une seule instruction. Les options de combinaisons sont les mêmes que pour la commande find.
| Critère |
Action |
| -a |
AND, ET logique |
| -o |
OR, OU logique |
| ! |
NOT, NON logique |
| (…) |
groupement des combinaisons. Les parenthèses doivent être vérouillées \(…\). |
$ test -d “rep1” -a -w “rep1” && exho “rep1: repertoire, droit en ecriture” rep1: repertoire, droit en ecriture
Syntaxe allégée
L e mot test peut être remplacé par les crochets ouverts et fermés « […] ». Il faut respecter un espace après et avant les crochets.
$ [ “$a” -lt “$b” ] && echo “$a est inferieur a $b”
10 est inferieur a 20
If … then … else
La structure if then else fi ‘est une structure de contrôle conditionnelle.
if
then
else
fi
On peut aussi préciser le elif, en fait un else if. Si la dernière condition n’est pas réalisée on en teste une nouvelle.
Exemple : test de la présence de paramètres
$ cat param4.sh
#!/usr/bin/sh
if [ $# -ne 0 ]
then
echo “$# parametres en ligne de commande”
else
echo “Aucun parametre; set alfred oscar romeo zoulou”
set alfred oscar romeo zoulou
fi
echo “Nombre de parametres : $#”
echo “Parametres : 1=$1 2=$2 3=$3 4=$4”
echo “Liste : $*”
$ ./param4.sh titi toto
2 parametres en ligne de commande
Nombre de parametres : 2
Parametres : 1=toto 2=titi 3= 4=
Liste : toto titi
$ ./param4.sh
Aucun parametre; set alfred oscar romeo zoulou
Nombre de parametres : 4
Parametres : 1=alfred 2=oscar 3=romeo 4=zoulou
Liste : alfred oscar romeo zoulou
Choix multiples case
La commande case esac permet de vérifier le contenu d’une variable ou d’un résultat de manière multiple.
case Valeur in
Modele1) Commandes ;;
Modele2) Commandes ;;
*) action_defaut ;;
esac
Le modèle est soit un simple texte, soit composé de caractères spéciaux. Chaque bloc de commandes lié au modèle doit se terminer par deux points-virgules.
Dès que le modèle est vérifié, le bloc de commandes correspondant est exécuté. L’étoile en dernière position (chaîne variable) est l’action par défaut si aucun critère n’est vérifié.
| Caractère |
Rôle |
| * |
Chaîne variable (même vide) |
| ? |
Un seul caractère |
| […] |
Une plage de caractères |
| [!…] |
Négation de la plage de caractères |
| | |
OU logique |
$ cat case1.sh
#!/usr/bin/sh
if [ $# -ne 0 ]
then
echo “$# parametres en ligne de commande”
else
echo “Aucun parametre; set alfred oscar romeo zoulou”
exit 1
fi
case $1 in
a*)
echo “Commence par a”
;;
b*)
echo “Commence par b”
;;
fic[123])
echo “fic1 fic2 ou fic3”
;;
*)
echo “Commence par n’importe”
;;
esac
exit 0
$ ./case1.sh “au revoir”
Commence par a
$ ./case1.sh bonjour
Commence par b
$ ./case1.sh fic2
fic1 ou fic2 ou fic3
$ ./case1.sh erreur
Commence par n’importe
Saisie de l’utilisateur
La commande read permet à l’utilisateur de saisir une chaîne et de la placer dans une ou plusieurs variable. La saisie est validée par entrée. read var1 [var2 …]
Si plusieurs variables sont précisées, le premier mot ira dans var1, le second dans var2, et ainsi de suite. S’il y a moins de variables que de mots, tous les derniers mots vont dans la dernière variable.
$ cat read.sh
#!/usr/bin/sh
echo “Continuer (O/N) ? \c”
read reponse
echo “reponse=$reponse”
case $reponse in
O)
echo “Oui, on continue”
;;
N)
echo “Non, on s’arrête”
exit 0
;;
*)
echo “Erreur de saisie (O/N)”
exit 1
;;
esac
echo “Vous avez continue. Tapez deux mots ou plus :\c”
read mot1 mot2
echo “mot1=$mot1\nmot2=$mot2”
exit 0
$ ./read.sh
Continuer (O/N) ? O
reponse=O
Oui, on continue
Vous avez continue. Tapez deux mots ou plus :salut les amis
mot1=salut
mot2=les amis
Les boucles
Elles permettent la répétition d’un bloc de commandes soit un nombre limité de fois, soit conditionnellement. Toutes les commandes à exécuter dans une boucle se placent entre les commandes do et done.
Boucle for
La boucle for ne se base pas sur une quelconque incrémentation de valeur mais sur une liste de valeurs, de fichiers …
for var in liste
do
commandes à exécuter
done
La liste représente un certain nombre d’éléments qui seront successivement attribuées à var.
Avec une variable
$ cat for1.sh
#!/usr/bin/sh
for params in $@
do
echo “$params”
done
$ ./for1.sh test1 test2 test3
test1
test2
test3
Liste implicite
Si on ne précise aucune liste à for, alors c’est la liste des paramètres qui est implicite. Ainsi le script précédent aurait pu ressembler à :
for params
do
echo “$params”
done
Avec une liste d’éléments explicite
$ cat for2.sh
#!/usr/bin/sh
for params in liste liste2
do
ls -l $params
done
$ ./for2.sh
-rw-r–r– 1 oracle system 234 Aug 19 14:09 liste
-rw-r–r– 1 oracle system 234 Aug 13 10:06 liste2
Avec des critères de recherche sur nom de fichiers :
$ cat for3.sh
#!/usr/bin/sh
for params in *
do
echo “$params \c”
type_fic=`ls -ld $params | cut -c1`
case $type_fic in
-) echo “Fichier normal” ;;
d) echo “Repertoire” ;;
b) echo “mode bloc” ;;
l) echo “lien symbolique” ;;
c) echo “mode caractere” ;;
*) echo “autre” ;;
esac
done
$ ./for3.sh
case1.sh Fichier normal
dump.log Fichier normal
for1.sh Fichier normal
for2.sh Fichier normal
for3.sh Fichier normal
lien_fic1 lien symbolique
lien_fic2 lien symbolique
liste Fichier normal
liste1 Fichier normal
liste2 Fichier normal
param.sh Fichier normal
param2.sh Fichier normal
param3.sh Fichier normal
param4.sh Fichier normal
read.sh Fichier normal
rep1 Repertoire
resultat.txt Fichier normal
toto.txt Fichier normal
voir_a.sh Fichier normal
Avec une substitution de commande
$ cat for4.sh
#!/usr/bin/sh
echo “Liste des utilisateurs dans /etc/passwd”
for params in `cat /etc/passwd | cut -d: -f1`
do
echo “$params ”
done
$ ./for4.sh
Liste des utilisateurs dans /etc/passwd
root
nobody
nobodyV
daemon
bin
uucp
uucpa
auth
cron
lp
tcb
adm
ris
carthic
ftp
stu
…
Boucle while
La commande while permet une boucle conditionnelle « tant que ». Tant que la condition est réalisée, le bloc de commande est exécuté. On sort si la condition n’est plus valable.
while condition
do
commandes
done
ou
while
bloc d’instructions formant la condition
do
commandes
done
Par exemple :
$ cat while1.sh
#!/usr/bin/sh
while
echo “Chaine ? \c”
read nom
[ -z “$nom” ]
do
echo “ERREUR : pas de saisie”
done
echo “Vous avez saisi : $nom”
Par exemple une lecture d’un fichier ligne à ligne :
#!/usr/bin/sh
cat toto.txt | while read line
do
echo “$line”
done
ou
#!/usr/bin/sh
while read line
do
echo “$line”
done < toto.txt
Boucle until
La commande until permet une boucle conditionnelle « jusqu’à ». Dès que la condition est réalisée, on sort de la boucle.
until condition
do
commandes
done
ou
until
bloc d’instructions formant la condition
do
commandes
done
Seq
La commande seq permet de sortir une séquence de nombres, avec un intervalle éventuel.
seq [debut] [increment] fin
ex :
$ seq 5
1
2
3
4
5
$ seq -2 3
-2
-1
0
1
2
3
$ seq 0 2 10
0
2
4
6
8
10
True et false
La commande true ne fait rien d’autre que de renvoyer 0. La commande false renvoie toujours 1. De cette manière il est possible de faire des boucles sans fin. La seule manière de sortir de ces boucles est un exit ou un break.
while true
do
commandes
exit / break
done
Break et continue
La commande break permet d’interrompre une boucle. Dans ce cas le script continue après la commande done. Elle peut prendre un argument numérique indiquant le nombre de boucles à sauter, dans le cadre de boucles imbriquées (rapidement illisible).
while true
do
echo “Chaine ? \c”
read a
if [ -z “$a” ]
then
break
fi
done
La commande continue permet de relancer une boucle et d’effectuer un nouveau passage. Elle peut prendre un argument numérique indiquant le nombre de boucles à relancer (on remonte de n boucles). Le script redémarre à la commande do.
Les fonctions
Les fonctions sont des bouts de scripts nommés, directement appelés par leur nom, pouvant accepter des paramètres et retourner des valeurs. Les noms de fonctions suivent les mêmes règles que les variables sauf qu’elles ne peuvent pas être exportées.
nom_fonction ()
{
commandes
return
}
Les fonctions peuvent être soit tapées dans votre script courant, soit dans un autre fichier pouvant être inclus dans l’environnement. Pour cela :
. nomfic
Le point suivi d’un nom de fichier charge son contenu (fonctions et variables dans l’environnement courant.
La commande return permet d’affecter une valeur de retour à une fonction. Il ne faut surtout par utiliser la commande exit pour sortir d’une fonction, sinon on quitte le script.
$ cat fonction
ll ()
{
ls -l $@
}
li ()
{
ls -i $@
}
$ . fonction
$ li
252 case1.sh 326 for4.sh 187 param.sh 897 resultat.txt
568 dump.log 409 lien_fic1 272 param2.sh 991 toto.txt
286 fonction 634 lien_fic2 260 param3.sh 716 voir_a.sh
235 for1.sh 1020 liste 42 param4.sh 1008 while1.sh
909 for2.sh 667 liste1 304 read.sh
789 for3.sh 1006 liste2 481 rep1
Expr
La commande expr permet d’effectuer des calculs sur des valeurs numériques, des comparaisons, et de la recherche dans des chaînes de texte.
| Opérateur |
Rôle |
| + |
Addition |
| – |
Soustraction |
| * |
Multiplication |
| / |
Division |
| % |
Modulo |
| != |
Différent. Affiche 1 si différent, 0 sinon. |
| = |
Egal. Affiche 1 si égal, 0 sinon. |
| < |
inférieur. Affiche 1 si inférieur, 0 sinon. |
| > |
supérieur. Affiche 1 si supérieur, 0 sinon. |
| <= |
inférieur ou égal. Affiche 1 si inférieur ou égal, 0 sinon. |
| >= |
supérieur ou égal. Affiche 1 si supérieur ou égal, 0 sinon. |
| : |
Recherche dans une chaîne. Ex expr Jules : J* retourne 1 car Jules commence par J. Syntaxe particulière : expr “Jules” : “.*” retourne la longueur de la chaîne. |
$ expr 7 + 3
10
$ expr 7 \* 3
21
$ a=`expr 13 ? 10`
$ echo $a
3
$ cat expr1.sh
#!/usr/bin/sh
cumul=0
compteur=0
nb_boucles=10
while [ “$compteur” -le “$nb_boucles” ]
do
cumul=`expr $cumul + $compteur`
echo “cumul=$cumul, boucle=$compteur”
compteur=`expr $compteur + 1`
done
$ ./expr1.sh
cumul=0, boucle=0
cumul=1, boucle=1
cumul=3, boucle=2
cumul=6, boucle=3
cumul=10, boucle=4
cumul=15, boucle=5
cumul=21, boucle=6
cumul=28, boucle=7
cumul=36, boucle=8
cumul=45, boucle=9
cumul=55, boucle=10
$ expr “Jules Cesar” : “.*”
11
Une variable dans une autre variable
Voici un exemple :
$ a=Jules
$ b=a
$ echo $b
a
Comment afficher le contenu de a et pas simplement a ? En utilisant la commande eval. Cette commande située en début de ligne essaie d’interpréter, si possible, la valeur d’une variable précédée par deux « $ », comme étant une autre variable.
$ eval echo \$$b Jules
Traitement des signaux
L a commande trap permet de modifier le comportement du script à la réception d’un signal.
| commande |
Réaction |
| trap ” signaux |
Ignore les signaux. trap ” 2 3 ignore les signaux 2 et 3 |
| trap ‘commandes’ signaux |
Pour chaque signal reçu exécution des commandes indiquées |
| trap signaux |
Restaure les actions par défaut pour ces signaux |
Commande « : »
La commande « : » est généralement totalement inconnue des utilisateurs unix. Elle retourne toujours la valeur 0 (réussite). Elle peut donc être utilisée pour remplacer la commande true dans une boucle par exemple :
while :
do
…
done
Cette commande placée en début de ligne, suivie d’une autre commande, traite la commande et ses arguments mais ne fait rien, et retourne toujours 0. Elle peut être utile pour tester les variables.
$ : ls
: ${X:?”Erreur”}
X : Erreur
Délai d’attente
La commande sleep permet d’attendre le nombre de secondes indiqués. Le script est interrompu durant ce temps. Le nombre de secondes et un entier compris entre 0 et 4 milliards (136 ans). $ sleep 10
 Sources de l’article
Sources de l’article